
Step3-VL-10B
Collection
2 items
•
Updated
•
9
STEP3-VL-10B is a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. Despite its compact 10B parameter footprint, STEP3-VL-10B excels in visual perception, complex reasoning, and human-centric alignment. It consistently outperforms models under the 10B scale and rivals or surpasses significantly larger open-weights models (10×–20× its size), such as GLM-4.6V (106B-A12B), Qwen3-VL-Thinking (235B-A22B), and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL.
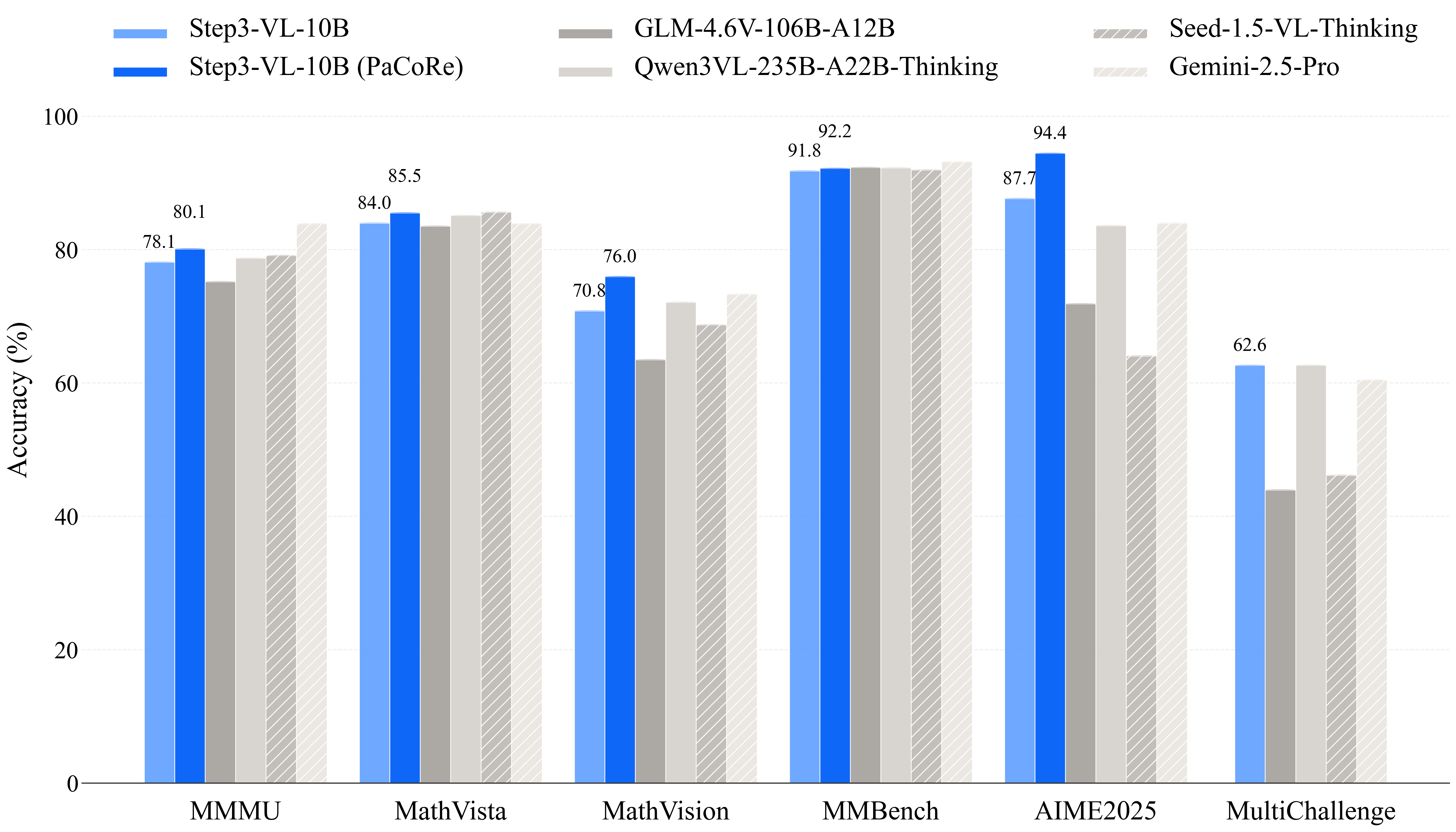
Figure 1: Performance comparison of STEP3-VL-10B against SOTA multimodal foundation models. SeRe: Sequential Reasoning; PaCoRe: Parallel Coordinated Reasoning.
The success of STEP3-VL-10B is driven by two key strategic designs:
| Model Name | Type | Hugging Face | ModelScope |
|---|---|---|---|
| STEP3-VL-10B-Base | Base | 🤗 Download | 🤖 Download |
| STEP3-VL-10B | Chat | 🤗 Download | 🤖 Download |
STEP3-VL-10B delivers best-in-class performance across major multimodal benchmarks, establishing a new performance standard for compact models. The results demonstrate that STEP3-VL-10B is the most powerful open-source model in the 10B parameter class.
| Benchmark | STEP3-VL-10B (SeRe) | STEP3-VL-10B (PaCoRe) | GLM-4.6V (106B-A12B) | Qwen3-VL (235B-A22B) | Gemini-2.5-Pro | Seed-1.5-VL |
|---|---|---|---|---|---|---|
| MMMU | 78.11 | 80.11 | 75.20 | 78.70 | 83.89 | 79.11 |
| MathVista | 83.97 | 85.50 | 83.51 | 85.10 | 83.88 | 85.60 |
| MathVision | 70.81 | 75.95 | 63.50 | 72.10 | 73.30 | 68.70 |
| MMBench (EN) | 92.05 | 92.38 | 92.75 | 92.70 | 93.19 | 92.11 |
| MMStar | 77.48 | 77.64 | 75.30 | 76.80 | 79.18 | 77.91 |
| OCRBench | 86.75 | 89.00 | 86.20 | 87.30 | 85.90 | 85.20 |
| AIME 2025 | 87.66 | 94.43 | 71.88 | 83.59 | 83.96 | 64.06 |
| HMMT 2025 | 78.18 | 92.14 | 57.29 | 67.71 | 65.68 | 51.30 |
| LiveCodeBench | 75.77 | 76.43 | 48.71 | 69.45 | 72.01 | 57.10 |
Note on Inference Modes:
SeRe (Sequential Reasoning): The standard inference mode using sequential generation (Chain-of-Thought) with a max length of 64K tokens.
PaCoRe (Parallel Coordinated Reasoning): An advanced mode that scales test-time compute. It aggregates evidence from 16 parallel rollouts to synthesize a final answer, utilizing a max context length of 128K tokens.
Unless otherwise stated, scores below refer to the standard SeRe mode. Higher scores achieved via PaCoRe are explicitly marked.
| Category | Benchmark | STEP3-VL-10B | GLM-4.6V-Flash (9B) | Qwen3-VL-Thinking (8B) | InternVL-3.5 (8B) | MiMo-VL-RL-2508 (7B) |
|---|---|---|---|---|---|---|
| STEM Reasoning | MMMU | 78.11 | 71.17 | 73.53 | 71.69 | 71.14 |
| MathVision | 70.81 | 54.05 | 59.60 | 52.05 | 59.65 | |
| MathVista | 83.97 | 82.85 | 78.50 | 76.78 | 79.86 | |
| PhyX | 59.45 | 52.28 | 57.67 | 50.51 | 56.00 | |
| Recognition | MMBench (EN) | 92.05 | 91.04 | 90.55 | 88.20 | 89.91 |
| MMStar | 77.48 | 74.26 | 73.58 | 69.83 | 72.93 | |
| ReMI | 67.29 | 60.75 | 57.17 | 52.65 | 63.13 | |
| OCR & Document | OCRBench | 86.75 | 85.97 | 82.85 | 83.70 | 85.40 |
| AI2D | 89.35 | 88.93 | 83.32 | 82.34 | 84.96 | |
| GUI Grounding | ScreenSpot-V2 | 92.61 | 92.14 | 93.60 | 84.02 | 90.82 |
| ScreenSpot-Pro | 51.55 | 45.68 | 46.60 | 15.39 | 34.84 | |
| OSWorld-G | 59.02 | 54.71 | 56.70 | 31.91 | 50.54 | |
| Spatial | BLINK | 66.79 | 64.90 | 62.78 | 55.40 | 62.57 |
| All-Angles-Bench | 57.21 | 53.24 | 45.88 | 45.29 | 51.62 | |
| Code | HumanEval-V | 66.05 | 29.26 | 26.94 | 24.31 | 31.96 |
We introduce how to use our model at inference stage using transformers library. It is recommended to use python=3.10, torch>=2.1.0, and transformers=4.57.0 as the development environment.We currently only support bf16 inference, and multi-patch for image preprocessing is supported by default. This behavior is aligned with vllm and sglang.
from transformers import AutoProcessor, AutoModelForCausalLM
key_mapping = {
"^vision_model": "model.vision_model",
r"^model(?!\.(language_model|vision_model))": "model.language_model",
"vit_large_projector": "model.vit_large_projector",
}
model_path = "stepfun-ai/Step3-VL-10B-Base"
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"},
{"type": "text", "text": "What's in this picture?"}
]
},
]
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
device_map="auto",
torch_dtype="auto",
key_mapping=key_mapping).eval()
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device)
generate_ids = model.generate(**inputs, max_new_tokens=1024, do_sample=False)
decoded = processor.decode(generate_ids[0, inputs["input_ids"].shape[-1] :], skip_special_tokens=True)
print(decoded)
If you find this project useful in your research, please cite our technical report:
@misc{huang2026step3vl10btechnicalreport,
title={STEP3-VL-10B Technical Report},
author={Ailin Huang and Chengyuan Yao and Chunrui Han and Fanqi Wan and Hangyu Guo and Haoran Lv and Hongyu Zhou and Jia Wang and Jian Zhou and Jianjian Sun and Jingcheng Hu and Kangheng Lin and Liang Zhao and Mitt Huang and Song Yuan and Wenwen Qu and Xiangfeng Wang and Yanlin Lai and Yingxiu Zhao and Yinmin Zhang and Yukang Shi and Yuyang Chen and Zejia Weng and Ziyang Meng and Ang Li and Aobo Kong and Bo Dong and Changyi Wan and David Wang and Di Qi and Dingming Li and En Yu and Guopeng Li and Haiquan Yin and Han Zhou and Hanshan Zhang and Haolong Yan and Hebin Zhou and Hongbo Peng and Jiaran Zhang and Jiashu Lv and Jiayi Fu and Jie Cheng and Jie Zhou and Jisheng Yin and Jingjing Xie and Jingwei Wu and Jun Zhang and Junfeng Liu and Kaijun Tan and Kaiwen Yan and Liangyu Chen and Lina Chen and Mingliang Li and Qian Zhao and Quan Sun and Shaoliang Pang and Shengjie Fan and Shijie Shang and Siyuan Zhang and Tianhao You and Wei Ji and Wuxun Xie and Xiaobo Yang and Xiaojie Hou and Xiaoran Jiao and Xiaoxiao Ren and Xiangwen Kong and Xin Huang and Xin Wu and Xing Chen and Xinran Wang and Xuelin Zhang and Yana Wei and Yang Li and Yanming Xu and Yeqing Shen and Yuang Peng and Yue Peng and Yu Zhou and Yusheng Li and Yuxiang Yang and Yuyang Zhang and Zhe Xie and Zhewei Huang and Zhenyi Lu and Zhimin Fan and Zihui Cheng and Daxin Jiang and Qi Han and Xiangyu Zhang and Yibo Zhu and Zheng Ge},
year={2026},
eprint={2601.09668},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2601.09668},
}
This project is open-sourced under the Apache 2.0 License.