Plug-and-Play Benchmarking of Reinforcement Learning Algorithms for Large-Scale Flow Control




Abstract
FluidGym presents a standalone, fully differentiable reinforcement learning benchmark for active flow control that operates without external CFD solvers and supports standardized evaluation protocols.
Reinforcement learning (RL) has shown promising results in active flow control (AFC), yet progress in the field remains difficult to assess as existing studies rely on heterogeneous observation and actuation schemes, numerical setups, and evaluation protocols. Current AFC benchmarks attempt to address these issues but heavily rely on external computational fluid dynamics (CFD) solvers, are not fully differentiable, and provide limited 3D and multi-agent support. To overcome these limitations, we introduce FluidGym, the first standalone, fully differentiable benchmark suite for RL in AFC. Built entirely in PyTorch on top of the GPU-accelerated PICT solver, FluidGym runs in a single Python stack, requires no external CFD software, and provides standardized evaluation protocols. We present baseline results with PPO and SAC and release all environments, datasets, and trained models as public resources. FluidGym enables systematic comparison of control methods, establishes a scalable foundation for future research in learning-based flow control, and is available at https://github.com/safe-autonomous-systems/fluidgym.
Community
FluidGym: Plug-and-Play Benchmarking of Reinforcement Learning Algorithms for Large-Scale Flow Control

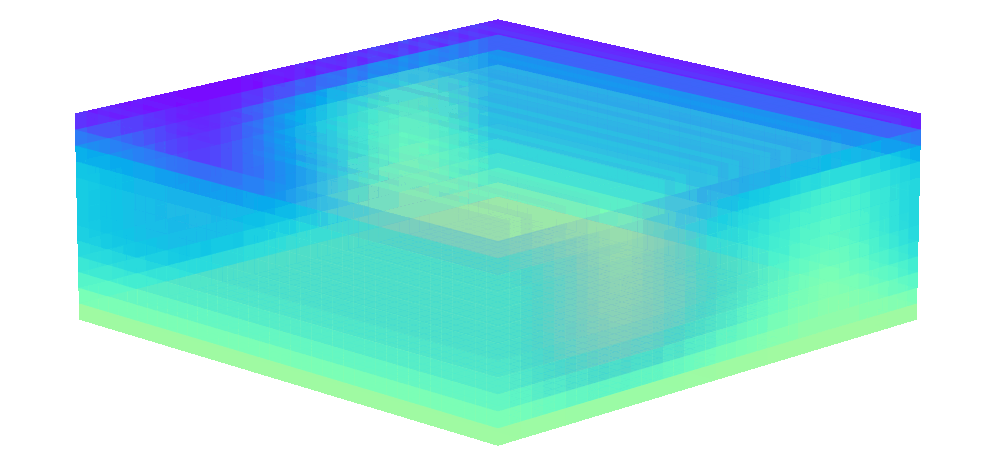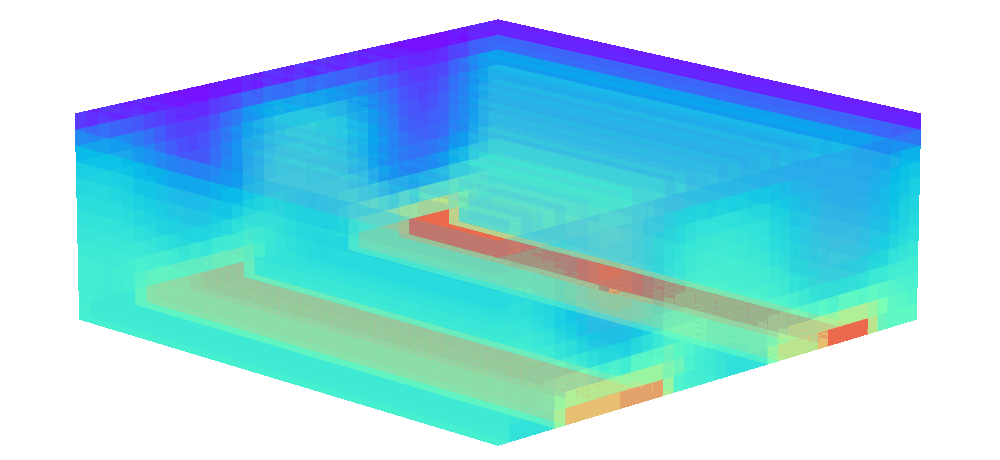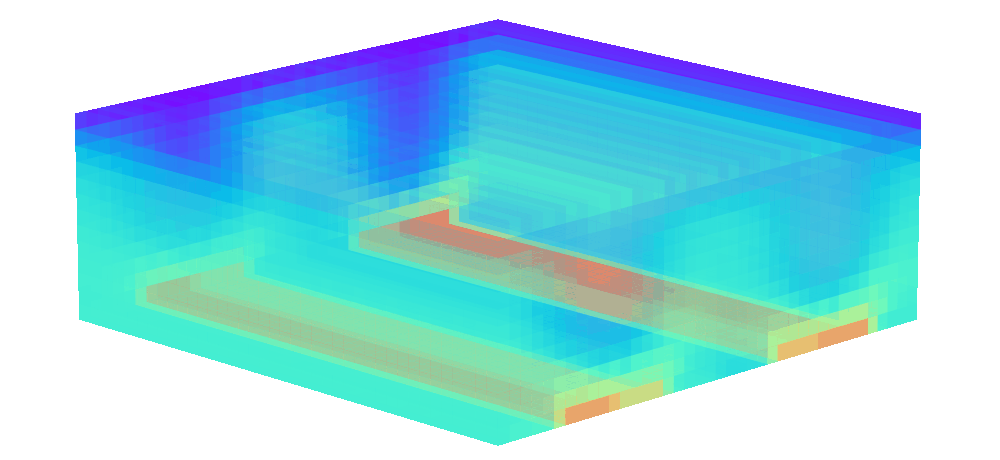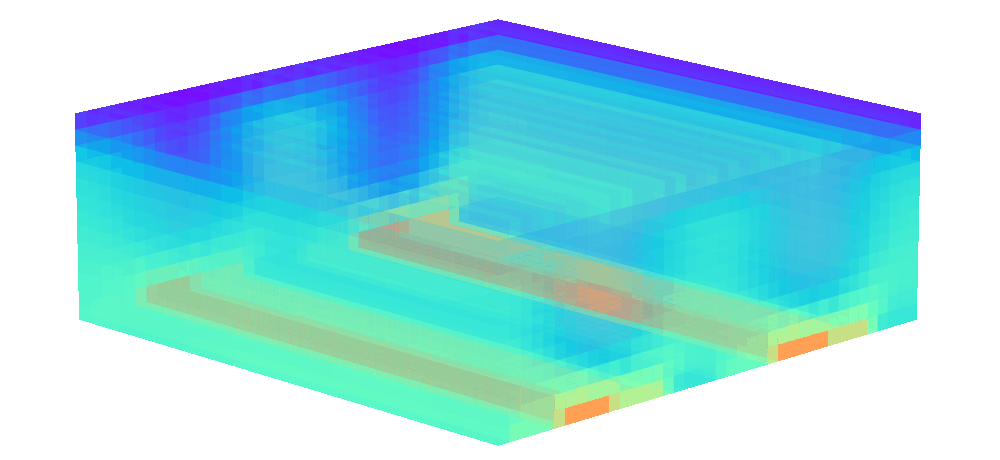


There is enormous potential for reinforcement learning and other data-driven control paradigms for controlling large-scale fluid flows. But RL research on such systems is often hindered by a complex and brittle software pipeline consisting of external solvers and multiple code bases, making this exciting field inaccessible for many RL researchers.
To tackle this challenge, we have developed a standalone, fully differentiable, plug-and-play benchmark for RL in active flow control, implemented in a single PyTorch codebase via PICT, without external solver dependencies.

We hope that this may be of interest to a large number of reinforcement learning researchers who are keen on assessing the most recent trends in basic RL research on a new set of challenging tasks, but otherwise find it difficult to enter the field of fluid mechanics
Paper: https://arxiv.org/abs/2601.15015v1
GitHub: https://github.com/safe-autonomous-systems/fluidgym
Models citing this paper 0
No model linking this paper
Datasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 0
No Space linking this paper