
File size: 3,795 Bytes
e37d336 | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 | ---
license: mit
pipeline_tag: text-generation
tags:
- glm4v
- AWQ
- vLLM
base_model:
- ZhipuAI/GLM-4.1V-9B-Thinking
base_model_relation: quantized
---
# GLM-4.1V-9B-Thinking-AWQ
基础型 [ZhipuAI/GLM-4.1V-9B-Thinking](https://www.modelscope.cn/models/ZhipuAI/GLM-4.1V-9B-Thinking)
### 【模型更新日期】
```
2025-07-03
1. 首次commit
2. 确定支持1、2、4卡的`tensor-parallel-size`启动
```
### 【依赖】
```
vllm==0.9.2
```
<div style="
background: rgba(255, 193, 61, 0.15);
padding: 16px;
border-radius: 6px;
border: 1px solid rgba(255, 165, 0, 0.3);
margin: 16px 0;
">
### 【💡2025-07-03 临时安装命令💡】
```
pip3 install -r requirements.txt
git clone https://github.com/zRzRzRzRzRzRzR/vllm.git
cd vllm
git checkout glm4_1-v
VLLM_USE_PRECOMPILED=1 pip install --editable .
```
</div>
### 【模型列表】
| 文件大小 | 最近更新时间 |
|---------|--------------|
| `6.9GB` | `2025-07-03` |
### 【模型下载】
```python
from modelscope import snapshot_download
snapshot_download('tclf90/GLM-4.1V-9B-Thinking-AWQ', cache_dir="本地路径")
```
### 【介绍】
# GLM-4.1V-9B-Thinking
<div align="center">
<img src=https://raw.githubusercontent.com/THUDM/GLM-4.1V-Thinking/99c5eb6563236f0ff43605d91d107544da9863b2/resources/logo.svg width="40%"/>
</div>
<p align="center">
📖 查看 GLM-4.1V-9B-Thinking <a href="https://arxiv.org/abs/2507.01006" target="_blank">论文</a> 。
<br>
💡 立即在线体验 <a href="https://huggingface.co/spaces/THUDM/GLM-4.1V-9B-Thinking-Demo" target="_blank">Hugging Face</a> 或 <a href="https://modelscope.cn/studios/ZhipuAI/GLM-4.1V-9B-Thinking-Demo" target="_blank">ModelScope</a> 上的 GLM-4.1V-9B-Thinking。
<br>
📍 在 <a href="https://www.bigmodel.cn/dev/api/visual-reasoning-model/GLM-4.1V-Thinking">智谱大模型开放平台</a> 使用 GLM-4.1V-9B-Thinking 的API服务。
</p>
## 模型介绍
视觉语言大模型(VLM)已经成为智能系统的关键基石。随着真实世界的智能任务越来越复杂,VLM模型也亟需在基本的多模态感知之外,
逐渐增强复杂任务中的推理能力,提升自身的准确性、全面性和智能化程度,使得复杂问题解决、长上下文理解、多模态智能体等智能任务成为可能。
基于 [GLM-4-9B-0414](https://github.com/THUDM/GLM-4) 基座模型,我们推出新版VLM开源模型 **GLM-4.1V-9B-Thinking**
,引入思考范式,通过课程采样强化学习 RLCS(Reinforcement Learning with Curriculum Sampling)全面提升模型能力,
达到 10B 参数级别的视觉语言模型的最强性能,在18个榜单任务中持平甚至超过8倍参数量的 Qwen-2.5-VL-72B。
我们同步开源基座模型 **GLM-4.1V-9B-Base**,希望能够帮助更多研究者探索视觉语言模型的能力边界。
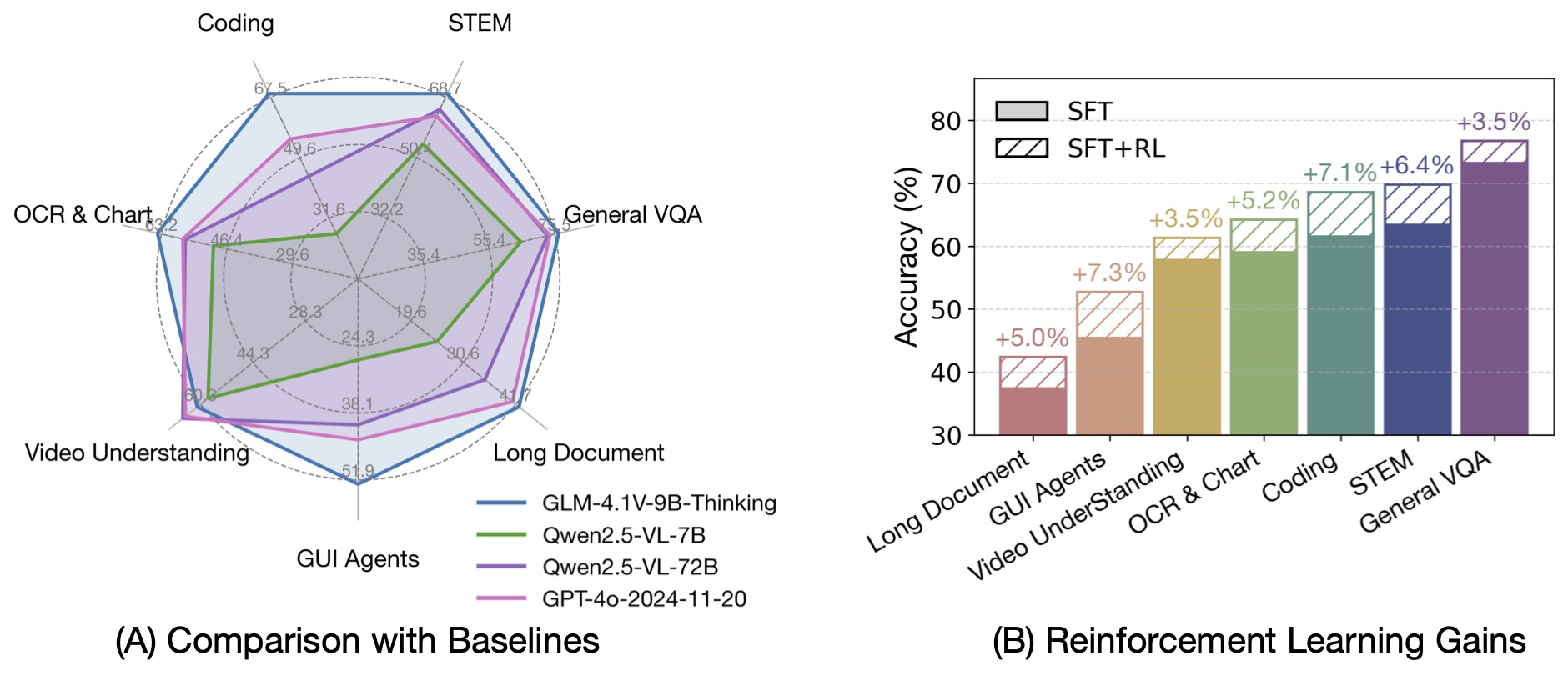
与上一代的 CogVLM2 及 GLM-4V 系列模型相比,**GLM-4.1V-Thinking** 有如下改进:
1. 系列中首个推理模型,不仅仅停留在数学领域,在多个子领域均达到世界前列的水平。
2. 支持 **64k** 上下长度。
3. 支持**任意长宽比**和高达 **4k** 的图像分辨率。
4. 提供支持**中英文双语**的开源模型版本。
## 榜单信息
GLM-4.1V-9B-Thinking 通过引入「思维链」(Chain-of-Thought)推理机制,在回答准确性、内容丰富度与可解释性方面,
全面超越传统的非推理式视觉模型。在28项评测任务中有23项达到10B级别模型最佳,甚至有18项任务超过8倍参数量的Qwen-2.5-VL-72B。

|